

Large learning models (LLMs) are a type of AI program that can recognise and generate text. An LLM is essentially a computer program that uses machine learning, a practice that involves feeding a program an enormous volume of data that enables it to recognise and interpret human languages or other types of complex data without human intervention [1].
LLM’s are currently being used in the following broad functions;
- Sentiment analysis
- DNA research
- Customer service (call centres)
- Chatbots
- Online searches (as seen with Chat GPT)
Despite the fanfare surrounding AI disruption, the use cases for LLM models within business operations remain low, primarily due to their early-stage development. However, a shift by developers to create smaller, task-centric reasoning models is expected to rapidly expand their implementation over the next 5 years.
On 20th January 2025, a relatively unknown Chinese AI software developer called DeepSeek released their latest AI reasoning model called R1. It quickly became the most downloaded app on the Apple Store, after independent assessments of R1’s capabilities showed results like the much larger LLM models like Chat-GPT4. [2]
Within a week of DeepSeek’s R1 launch, the US Nasdaq market fell by 3.5% on January 28th, while some of the world’s leading technology hardware companies, including Nvidia, Broadcom, SK Hynix and ARM Holdings, fell by 10-20% in a single trading session.
What changed overnight to trigger this sharp selloff?
The selloff of technology hardware companies, like NVIDIA, Broadcom and ARM, resulted from information contained in DeepSeek’s R1 model white paper, released on 20th January. In this report [3], DeepSeek stated that R1 had the following capabilities;
This white paper suggested that DeepSeek had reinvented AI training at a substantially lower cost, both in terms of computer hardware requirements and model development [4][5].
Did this mean that demand for specialised chips like NVIDIA GPUs would be substantially lower than current expectations? Let us come back to this question later.
Who is DeepSeek?
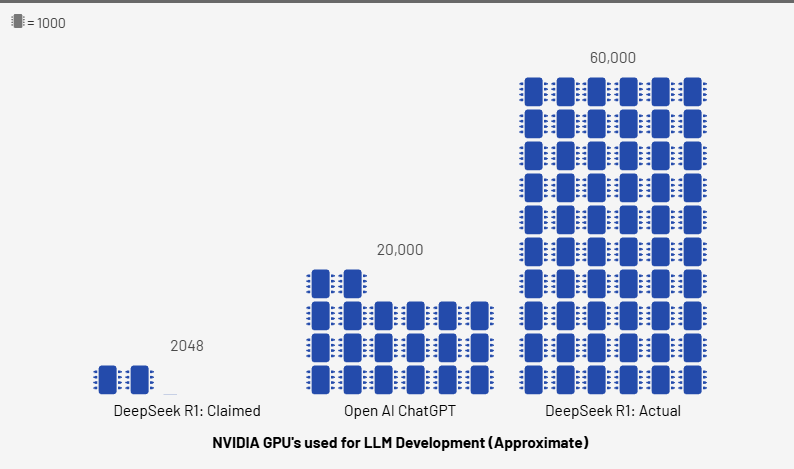
DeepSeek was started in 2021 by High-Flyer, a mainland Chinese hedge fund that was an early adopter of AI in its trading strategies. Over the past 4 years, High-Flyer has invested US$1.6bn, acquiring up to 60,000 NVIDIA GPU chips and other computer hardware, with an additional US$1bn of operating costs incurred over this period [6].

Now that the dust has settled after the market collapse on January 28th, substantial evidence has emerged that raises serious doubts about the validity of DeepSeek’s claimed achievements.
It turns out the $6m R1 development cost does not include the substantial operating and computer hardware expense requirements in its calculation. The figure appears to be just related to direct model training costs.
Furthermore, given R1’s performance relative to OpenAI and High-Flyer’s capabilities (60,000 GPUs), it also seems likely that they used a much larger number of NVIDIA GPUs to train R1, refuting their lower cost and lower hardware requirement claims.
If we consider performance, DeepSeek’s R1 achieving comparable reasoning outcomes as the much larger OpenAI model (GPT-4 and o-1) is most likely a function of the rapid improvements being achieved with newer AI reasoning algorithms undergoing model training. Dario Amodei, the CEO of AI research company Anthropic that built Claude AI (a competing LLM model), has suggested that algorithm improvements can deliver 10-fold annual improvements in efficiency (90% reduction in compute capacity each year for the same outcome) while AI is still in its infancy [7].
With DeepSeek released 5 months later than Open AI’s latest model (o1), its ability to compete with the more established models is most likely explained by the algorithm efficiency gains outlined by Dario Amodei.
This is supported by the results of “Humanity’s Last Exam”, a newly created test designed by an international team of AI experts to create a standard benchmark to measure AI model reasoning performance. OpenAI’s latest model, o3-mini (launched February 5th) achieved the highest score of 13% versus 9.4% for DeepSeek R1. OpenAI’s ‘Deep Research’ tool scored an even more impressive 26.6% (though as the tool has functions not included by the other model, this is a less relevant comparison) [8].
What does this mean for investors?
The world of AI is challenging for most investors to understand, given its rapid pace and early stage of development. Market leadership remains unknown, evidenced by the enormous stock market reaction to new, much smaller competitors like DeepSeek that may challenge the larger US tech giants operating in the space.
With this uncertainty comes volatility in share prices as investors react to each piece of positive or negative news. Taking the time to properly analyse news flow is critical before deciding on how to respond (buy, sell, hold). Investors who panicked and sold out of their US technology stock positions during the January 28 crash missed the strong rebound over the following 2 weeks, with NVIDIA up 13% (-7% below 25/1 price) and Broadcom up 19% (-4% below 25/1 price).
It is also important for investors to build confidence in the key companies best positioned to benefit from rising investment in the sector. Reviewing the annual capital expenditure budgets for the four big data centre operators and chip hardware makers (Google, Meta, Microsoft and TSMC), we can see that their combined capex has grown from US$88bn in 2021 to US$240bn in 2025 (29% CAGR).
Over the next 4 years, these four tech giants are forecast by investment banking analysts to accumulate over US$1.2 Trillion of free cash flow despite committing to spend almost US$1 Trillion on capital expenditure, mostly on AI-enabled data centres. They have the balance sheet capacity and see the opportunity to keep expanding and adding new data centre capacity that’s increasingly integrated with their AI reasoning models.
President Trump’s January announcement of Stargate, a US$500b AI-investment initiative to build cutting-edge data centres and AI-related software to serve the mainland US, also adds substantial new demand for AI-related computer hardware. Similarly, governments around the world, including the EU and China, have also committed to building in-country AI reasoning models to ensure they can compete with other nations’ capabilities.
All of this suggests that investors could consider exposure to the leading technology hardware supply chain companies, given the likely direction of future demand growth. While DeepSeek’s launch caused a market selloff, the recovery in most technology share prices back towards previous highs suggests its impact will be muted on long-term demand.
At Carrara, we are closely monitoring the evolving landscape of artificial intelligence and its implications for global markets. If you would like to discuss how our thematic investment approach is considering developments in AI technologies, or if you are interested in learning more about our strategies in this sector, please don’t hesitate to contact us for further information.

